CLOSE
About Elements
私たち田中貴金属は、貴金属のリーディングカンパニー。
社会の発展を支える先端素材やソリューション、
それらが生まれた開発ストーリー、技術者たちの声、そして経営理念とビジョンーー
Elementsは、「貴金属を究める」をスローガンに、
より良い社会、豊かな地球の未来につながるインサイトを発信するWEBメディアです。

先端素材で社会の発展を支える、
田中貴金属の情報発信メディア






未来の機械はヒトの脳のように思考し、ヒトの動きを認識する


脳から着想を得た、体性感覚/視覚連合学習フレームワーク。出典:Wang et al.
シンガポールにある南洋理工大学とシドニー工科大学の研究チームが、ヒトのジェスチャーを認識できる機械学習アーキテクチャを開発した。『Nature Electronics』誌に論文として掲載されたこの新たなアーキテクチャは、ヒトの脳のはたらきにヒントを得てつくられたもので、伸縮性のある歪みセンサーでキャプチャされた画像を分析する。
研究チームの一員であるチェン・シャオドン(Chen Xiaodong)はTechXploreの取材に対し、「発想の起点は、ヒトの脳の情報処理システムだ」と述べた。「ヒトの脳において、思考、計画、インスピレーションといった高次知覚活動は、特定の感覚情報だけに依存するのではなく、複数の感覚情報を包括的に統合したものに由来する。そこでわたしたちは、視覚情報と体性感覚情報を組み合わせ、高精度のジェスチャー認識を実現することを試みた」
実際的なタスクに取り組む際のヒトは一般的に、周囲の環境から収集した視覚情報と、体性感覚情報を統合する。これら2種類の情報は相補的であり、両者を組み合わせることで、解決しようとしているタスクのさまざまな要素をよりよく把握することができる。
チェンらは、ヒトのジェスチャーを認識する技術を開発するにあたり、複数のセンサーが収集する異なるタイプの感覚情報を統合できることを重視した。彼らは最終目標を、きわめて高精度にヒトのジェスチャーを認識できるアーキテクチャの構築と定めた。
「この目的を達するためわたしたちは、手のジェスチャーの体性感覚データを現行のウェアラブルセンサーよりも正確に収集できる、伸縮性があり変形可能なセンサーを設計・製造し、センサーデータの質を向上させた」とチェンは説明する。「さらに、わたしたちが開発したBSV(bioinspired somatosensory-visual/生体模倣された体性感覚、視覚)学習アーキテクチャを使えば、視覚情報と体性感覚情報を整合性のある形に統合することができる。この処理は、ヒトの脳のなかで行われる、体性感覚と視覚の階層的統合に似ているものだ」
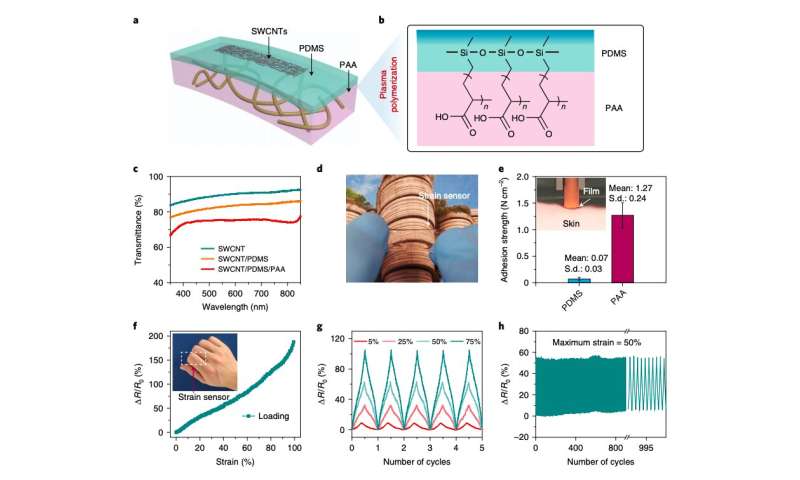
変形可能で伸縮性があり、皮膚に接着できる透明な歪みセンサー。出典:Wang et al.
チェンらが開発したBSV学習アーキテクチャは、いくつかの点で、ヒトの脳が体性感覚情報と視覚情報を統合する方法を再現したものと言える。第一に、脳を模倣した多層的かつ階層的な構造を持っており、生物の神経系の代わりに人工ニューラルネットワークを備えている。
さらに、アーキテクチャの下位構造をなすいくつかのネットワークは、脳の神経系が処理するのと同じ様式の感覚データ処理を担う。例えば、畳み込みニューラルネットワーク(Convolutional Neural Network:CNN)のあるセクションは畳み込み処理に特化しているが、これは生物神経系の局所受容野の機能を人工的に再現したもので、結果的に、ヒト脳内の視覚野で行なわれる視覚情報処理の初期段階を模倣している。
最後に、研究チームが考案したアーキテクチャは、新たに開発された「スパース(sparse)なニューラルネットワーク」を使って、複数の機能を統合している。このネットワークは、脳内にある多感覚ニューロンがどのようにして、視覚情報と体性感覚情報の間の、エネルギー効率の良い初期の相互作用を表すかを再現している。
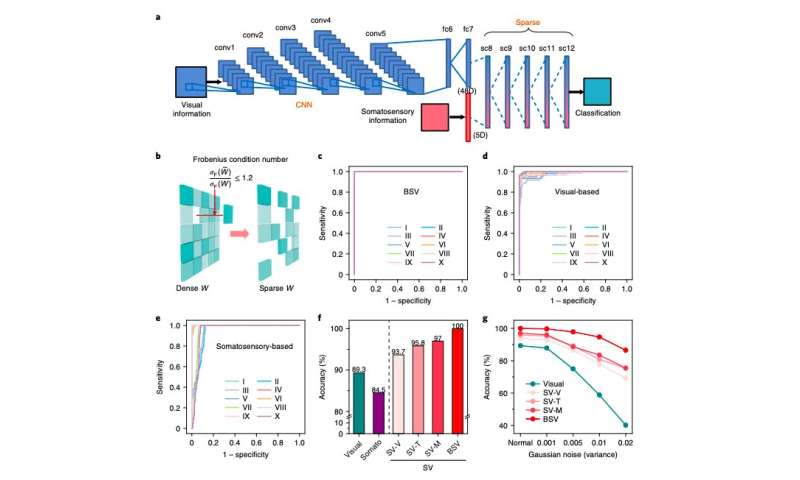
BSV連合学習による特徴分類。出典: Wang et al.
「われわれが開発した技術には、3つのユニークな特徴がある」と、チェンは説明する。「第一に、視覚情報と体性感覚情報の初期の相互作用を処理できる点。第二に、畳み込みニューラルネットワークが実行する畳み込み演算が、生物の神経系における局所受容野の機能に類似していて、階層性のある深層空間特徴を自動的に学習し、オリジナルの画像から推移不変の特徴を抽出できる点。最後に、フロベニウス条件数に依存した新たな刈り込み戦略を導入することで、エネルギー効率の良いスパースなニューラルネットワークを実現している点だ」
チェンらが開発したBSV学習アーキテクチャは、一連の初期性能テストにおいて、ユニモーダル認識アプローチ(視覚情報または体性感覚情報のどちらか一方だけを処理する方法)よりも優れた成績を示した。さらに注目すべき点として、過去に開発された3つのマルチモーダル認識アーキテクチャ、すなわち加重平均統合(SV-V)、加重注意統合(SV-T)、加重乗算統合(SV-M)よりも正確に、ヒトのジェスチャーを識別できた。
「われわれの生体模倣に基づく学習アーキテクチャは、ユニモーダル認識アプローチ(視覚ベースまたは体性感覚ベース)や、一般的なマルチモーダル認識アプローチ(SV-V、SV-T、SV-M)を上回る認識精度を達成できる」と、チェンは言う。「さらに、画像にノイズが多かったり、露出不足や露出過多といった理想的ではない条件においても、高い認識精度を維持できる。(こうした条件下では、BSVの精度がわずかに低下するものの、ほかの技術に比べると、はるかに影響を受けにくかった)」
今回開発された、脳に着想を得たアーキテクチャは、将来的に多くの実世界環境に導入される可能性がある。例えば、患者のボディランゲージを読み取ることができる医療用ロボットの開発や、より高度な仮想現実(VR)、拡張現実(AR)、エンターテインメント関連技術の開発への応用が考えられる。
「われわれのアーキテクチャは、生体模倣に基づく独自の特性により、既存のほとんどのアプローチよりも優れた性能をもつことが実験結果から裏付けられた」と、チェンは言う。「次のステップは、生体模倣による視覚データとセンサーデータの統合を応用した、VRとARのシステムを構築することだ」
詳細情報:Ming Wang et al. Gesture recognition using a bioinspired learning architecture that integrates visual data with somatosensory data from stretchable sensors(視覚データと伸縮可能なセンサー由来の体性感覚データを統合する生体模倣学習アーキテクチャを用いたジェスチャー認識) Nature Electronics (2020) DOI: 10.1038/s41928-020-0422-z
© 2020 Science X Network
原文:A brain-inspired architecture for human gesture recognition (2020年7月14日発行、同日にhttps://techxplore.com/news/2020-07-brain-inspired-architecture-human-gesture-recognition.html より取得)
当記事は著作権対象です。個人の学習または研究を目的とした公正利用の場合を除き、明示的許可のない部分・全体複製は禁じられています。当コンテンツは情報提供だけを目的に発行されました。
この記事は、Tech Xploreが執筆し、Industry Diveパブリッシャーネットワークを通じてライセンスされたものです。ライセンスに関するお問い合わせはlegal@industrydive.comまでお願いいたします。